JNH资讯
发布日期:2026-03-18 15:12 点击次数:130

每经记者:兰素英每经剪辑:王嘉琦
连年来,AI大模子的编程才调突飞大进,各大AI厂商在编程基准测试上你追我赶,不断刷新记录。这让不少次第员开动担忧:AI是不是很快就要抢走咱们的饭碗了?
但是,中山大学与阿里巴巴调治发布的一项最新有筹商给次第员们吃下了一颗“定心丸”。
3月4日,两家机构调治发布了一项评测扫尾。这项测试名为“SWE-CI:通过握续集成评估智能体调节代码库的才调”(SWE-CI:EvaluatingAgentCapabilitiesinMaintainingCodebasesviaContinuousIntegration),初次对包括Anthropic、OpenAI、Kimi和DeepSeek等8家主流厂商的18款AI大模子的遥远代码调节才调进行了严苛的系统性评估测试。
金沙电玩城app官方下载测试包含100项任务,总Token破钞超100亿。扫尾泄露,ClaudeOpus系列轮廓弘扬领跑。
在落拓性能退化方面,千问、DeepSeek、MiniMax、Kimi和豆包等大大皆AI大模子的弘扬明显欠安。也即是说,AI在遥远代码调节流程中,可能将代码“越改越糟”。
100项任务!中国团队推出行家首个评估AI大模子遥远代码调节才调的评测系统
遥远以来,AI编程才调的主流评测基准的共同特色是快照式评测,以“单次接管需求、一次性输出搞定决策”为中枢。
但是,这种评估神志仅锤真金不怕火大模子是否能写出功能正确的代码,无法反馈实在软件设备中握续迭代、遥远调节的中枢需求。
在推行中,教训的软件很少是一蹴而就的,而是遥远调节的扫尾。雷曼定律标明,软件质料会跟着调节的进行而当然着落。而调节职责占软件生命周期总资本的60%到80%。
为评估AI在遥远代码调节中的弘扬,中山大学与阿里巴巴团队调治推出了SWE‑CI评测基准。这是行家首个突出评估AI智能体在遥远代码调节弘扬的评测系统,它不再清闲于捕快AI编程的“一次性正确”,而是评估AI是否像实在的软件工程师雷同,在数月以至数年的设备流程中握续保握代码质料。
SWE‑CI基准测试的构建经过四层严格筛选,最终酿成高质料评测集。
有筹商团队先从GitHub全网的Pytho代码库中筛选出调节三年以上、星标超500、包含依赖文献和完好单位测试套件,以及接管MIT/Apache‑2.0等宽松契约的4923个代码库;再索要依赖强健、代码修改量超1000行的提交对,得到8311个候选样本;通过自动构建Docker环境与自诞生依赖机制,保留1458组可运行候选对;临了经测试启动校验、通过率各异筛选、时刻跨度与提交量排序,详情100项最终任务。
有筹商团队尽心构建的100项任务中,每项任务皆对应着实在全国中一个软件形态的完好进化历程。这些形态平均跨越233天的设备时刻,包含71次麇集的代码提交记录。团队还想象了一个小巧的“架构师-次第员”双智能体引诱机制。想象的灵感来自实在软件团队中常见的单干模式:架构师讲求分析需乞降制定技巧决策,次第员讲求具体的代码设备。
为适配遥远迭代评测,SWE‑CI提倡了“归一化变化”与“EvoScore(进化得分)”两大中枢筹算。
“归一化变化”以测试用例通过数为基础,将代码景况映射到[-1,1]区间,正向暗示功能进步,负向暗示出现功能退化。
EvoScore更侧重臆度AI大模子在翌日修改任务中的弘扬。
实测扫尾:ClaudeOpus断层领跑,大大皆大模子在75%的任务中会龙套原有代码
有筹商团队对8家公司——月之暗面、Anthropic、智谱、千问、MiniMax、DeepSeek、OpenAI和豆包——的18个主流AI大模子进行了系统性测试,累计破钞了高出100亿Token的测试数据。这一实验限度在AI编程评估范围号称史无先例。
有筹商扫尾泄露,从时刻维度来看,AI大模子在代码调节才调上的进化呈现出明显的加快弧线。
从下图不错发现,团结厂商的大模子新版块广阔强健高于前一代,且2026年后的跃升幅度权贵扩大,EvoScore更高。这标明,现时大模子的代码才调正从静态颓势诞生,快速向握续、遥远的代码调节演进。
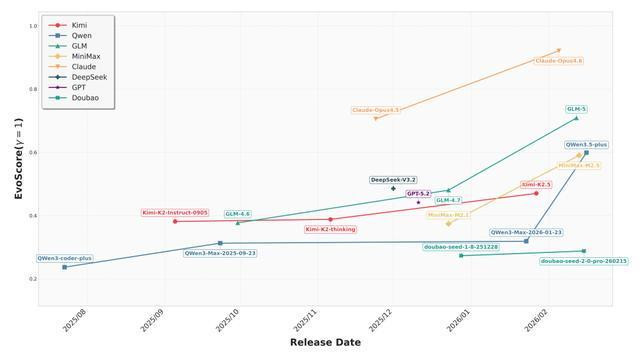
在所有参评大模子中,ClaudeOpus系列弘扬最为凸起,从Claude-opus-4.5到Claude-opus-4.6,金年会官网首页入口其EvoScore跃升至约0.9的高位,明显拉开了与所有竞争敌手的差距。
中国的AI大模子中,智谱GLM系列跨越权贵,成为第二梯队中最具竞争力的选手。紧随自后的是Qwen和MiniMax,合座趋势向好。而Kimi和豆包虽有进步,但可贵冲突。
有筹商还发现,不同厂商在大模子教化战略上偏好存在明显分化。
具体而言,MiniMax、DeepSeek以及OpenAI的GPT系列大模子更偏好遥远效益,泄露出其在遥远代码调节任务中的上风。这意味着,这类大模子在生成代码时,更倾向于接管故意于遥远演进与强健性的战略,而非追求短期诞生的最优解。
比拟之下,Kimi与智谱GLM系列更偏向于短期顺利的优化旅途。
而千问、豆包以及Claude系列大模子则呈现出另一种特征:其教化战略在短期着力与遥远调节之间赢得了一定均衡。
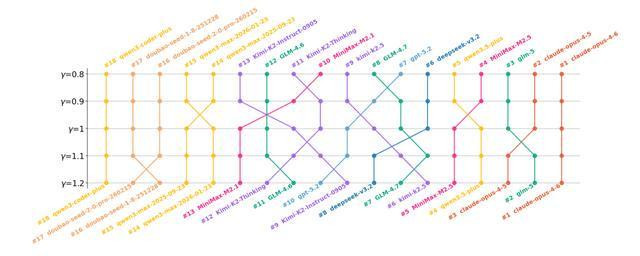
跟着权重参数γ的变化,各个大模子的排行也随之发生权贵调理。当γ>1时,大模子排行越高,其代码库调节才调越强。图片
另外,有筹商还有一项关节发现:在遥远代码调节中,所有大模子在灵验落拓性能退化(Regression)方面皆弘扬欠安。
性能退化是臆度软件质料强健性的中枢筹算。如若某个单位测试在代码更新前一经通过,而更新后失败了,则判定该变更触发了性能退化。一朝出现性能退化,不仅会平直影响用户体验,在遥远调节流程中,跟着修改次数积聚,还可能导致系统质料系统性退化。
有筹商团队测量了“零退化率”——即在通盘调节流程中透顶莫得龙套原有功能的任务比例。零退化率越高,调节的系统越强健。
有筹商扫尾标明,在所有参与测试的18个大模子中,惟有Anthropic的ClaudeOpus大模子保握了50%以上的零退化率,大大皆大模子的零退化率皆低于25%。
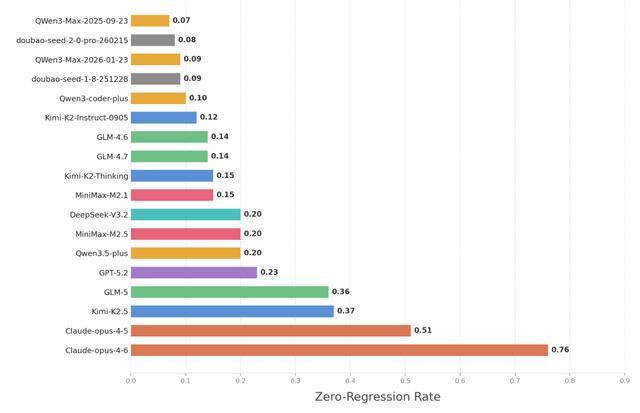
具体而言,Claude-opus-4.6以76%的零退化率遥遥最初。这意味着在绝大大皆测试场景中,其性能能够保握强健。Claude-opus-4.5以51%位列第二。比拟之下,Kimi-K2.5(37%)与GLM-5(36%)弘扬接近,组成第二梯队,虽具备一定强健性,但与头部大模子仍存在权贵差距。
包括GPT-5.2、Qwen3.5-plus、MiniMax-M2.5和DeepSeek-V3.2在内的其余14个AI大模子的零退化率皆在25%以下,这意味着在遥远代码调节流程中,大模子在高出75%的任务中会龙套蓝本普通的代码功能,激勉性能退化问题。
但从版块迭代的角度看,头部厂商的AI大模子正快速跨越。举例,Claude-opus系列的“零退化率”从4.5版块的51%进步至4.6版块的76%,智谱GLM系列从GLM-4.6和GLM-4.7的14%跃升至GLM-5的36%。
但即便如斯,绝大大皆大模子仍难以在遥远代码调节中阻绝性能退化问题,距离可靠的自动化遥远设备仍有明显差距。
SWECI基准测试扫尾的发布,让行业相识到,“写代码”和“调节代码”是两种截然有异的才调。关于大模子厂商而言,握续优化可调节性、性能退化落拓、架构想象才调金年会(JinNianHui)体育,大致将是赢得下半场竞争的关节。

 备案号:
备案号: